
In an earlier post, I set out proposal for measuring distance or (dis)similarity between desire-states (if you like, between utility functions defined over a vector of propositions). That account started with the assumption that we measured strength of desire by real numbers. And the proposal was to measure the (dis)similarity between desires by the squared euclidean distance between the vectors of desirability at issue. If 
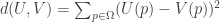
In that earlier post, I linked this idea to “value” dominance arguments for the characteristic equations of causal decision theory. Today, I’m thinking about compromises between the desires of a diverse set of agents.
The key idea here is to take a set A of m utility functions 

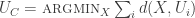
So what is the X which minimizes the following?

Rearranging:

This is a sum of m summands, each of which is positive. So you find the minimum value by minimizing each summand. And to minimize the ith summand we differentiate and set the result to zero:
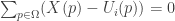
This gives us the following value of X(p):

This tells us exactly what value
Suppose our group of agents is faced with a collective choice between a number of options. Then one option O is strictly preferred to the other options according to the compromise utility
That’s really all I want to observe for today. A couple of finishing up notes. First, I haven’t found a place where this mechanism for compromise choice is set out and defended (I’m up for citations though, since it seems a natural idea). Second, there is at least an analogous strategy already in the literature. In Gaertner’s A Primer in Social Choice Theory he discusses (p.112) the Kemeny procedure for social choice, which works on ordinal preference rankings over options, and proceeds by finding that ordinal ranking which is “closest” to a profile of ordinal rankings of the options by a population. Closeness is here measured by the Kemeny metric, which counts the number of pairwise preference reversals required to turn one ranking into the other. Some neat results are quoted: a Condorcet winner (the option that would win against all others in a purality vote) if it exists is always top of the Kemeny compromise ranking. As the Kemeny compromise ranking stands to the Kemeny distance metric over sets of preference orderings, so the utilitarian utility function stands to the square-distance divergence over sets of cardinal utility functions.
I’ve been talking about all this as if every aspect of utility functions were meaningful. But (as discussed in recent posts) some disagree. Indeed, one very interesting argument for utilitarianism has as a premise that utility functions are invariant under level-changes—i.e the utility function U and the utility function V represent the same underlying desire-state if there is a constant 


On the one hand, on the picture just mentioned, these are supposed to be two representations of the same underlying state (if level-boosts are just a “choice of unit”) and on the other hand, they have positive dissimilarity by the distance measure I’m working with.
Now, as I’ve said in previous posts, I’m not terribly sympathetic to the idea that utility functions represent the same underlying desire-state when they’re related by a level boost. I’m happy to take the verdict of the squared euclidean similarity measure literally. After all, it was only one argument for utilitarianism as a principle of social choice that required the invariance claim–the reverse implication may not hold. In this post we have, in effect, a second independent argument for utilitarianism as a social choice mechanism that starts from a rival, richer preference structure.
But what if you were committed to the level-boosting invariance picture of preferences? Well, really what you should be thinking about in that case is equivalence classes of utility functions, differing from each other solely by a level-boost. What we’d really want, in that case, is a measure of distance or similarity between these classes, that somehow relates to the squared euclidean distance. One way forward is to find a canonical representative of each equivalence class. For example, one could choose the member of a given equivalence class that is closest to the null utility vector–from a given utility function U, you find its null-closest equivalent by subtracting a constant equal to the average utility it assigns to propositions: 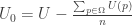
Another way to approach this is to look at the family of squared euclidean distances between level-boosted equivalents of two given utility functions. In general, these distances will take the form

(Where 
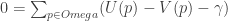
which rearranging gives:

Working backwards, set 
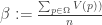

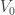
This is a neat result to have in hand. I think the “minimum distance between two equivalence classes” is better motivated than simply picking arbitrary representatives of the two families, if we want a way of extending the squared-Euclidean measure of similarity to utilities which are assumed to be invariant under level boosts. But this last result shows that we can choose (natural) representatives of the equivalence classes generated and measure the distance between them to the same effect. It also shows us that the social choice compromise which minimizes distance between families of utility can be found by (a) using the original procedure above for finding the utility function
I want to emphasize again: my own current view is that the complexity intoduced in the last few paragraphs is unnecessary (since my view is that utilities that differ by constant factors from one another represent distanct desire-states). But I think you don’t have to agree with me on this matter to use the minimum distance compromise argument for utilitarian social choice.
