
The previous post discusses a “distance minimizing” way of picking a compromise between agents with a diverse set of utilities. If you measure distance (better: divergence) between utility functions by square Euclidean distance, then a utilitarian compromise pops out.
I wanted now to discuss briefly a related set of results (I’m grateful for pointers and discussion with Richard Pettigrew here, though he’s not to blame for any goofs I make along the way). The basic idea here is to use a different distance/divergence measure between utilities, and look at what happens. One way to regard what follows is as a serious contender (or serious contenders) for measuring similarity of utilities. But another way of looking at this is as an illustration that the choice of similarity I made really has significant effects.
I borrowed the square Euclidean distance analysis of similarity from philosophical discussions of similarity of belief states. And the rival I now discuss is also prominent in that literature (and is all over the place in information theory). It is (generalized) Kullback-Leibler relative entropy (GKL), and it gets defined, on a pair of real valued vectors U,V in this way:
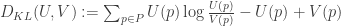
Note that when the vectors are each normalized to the same quantity, the sum of U(p) over all p is equal to the sum of V(p) over all p, and so two latter summands cancel. In the more general case, they won’t. Kullback-Leibler relative entropy is usually applied with U and V being probability functions, which are normalized, so you normally find it in the form where it is a weighted sum of logs. Notoriously, GKL is not symmetric: the distance from U to V can be different from the distance to U from V. This matters; more anon.
(One reason I’m a little hesitant with using this as a measure of similarity between utilities in this context is the following. When we’re using it to measure similarity between beliefs or probability functions, there’s a natural interpretation of it as the expectation from U’s perspective of difference between the log of U and the log of V. But when comparing utilities rather than probabilities means we can’t read the formula this way. It feels to me a bit more of a formalistic enterprise for that reason. Another thing to note is that taking logs is well defined only when the relevant utilities are positive, which again deserves some scrutiny. Nevertheless….)
What happens when we take GKL as a distance (divergence) measure, and then have a compromise between a set of utilities by minimizing total sum distance from the compromise point to the input utilities? This article by Pettigrew gives us the formal results that speak to the question. The key result is that the compromise utility 


Where the utilitarian compromise utilities arising from squared euclidean distance similarity look to the sum of individual utilities, this compromise looks at the product of individual utilities. It’s what’s called in the social choice literature a symmetrical “Nash social welfare function” (that’s because it can be viewed as a special case of a solution to a bargaining game that Nash characterized: the case where the “threat” or “status quo” point is zero utility for all). It has some interesting and prima facie attractive features—it prioritizes the worse off, in that a fixed increment of utility will maximize the product of everyone’s utilities if awarded to someone who has ex ante lowest utility. It’s also got an egalitarian flavour, in that you maximize the product of a population’s utilities by dividing up total utility evenly among the population (contrast utilitarianism, where you can distribute utility in any old way among a population and get the same overall sum, and so any egalitarian features of the distribution of goods have to rely on claims about diminishing marginal utility of those goods; which by the same token leaves us open to “utility monsters” in cases where goods have increasing utility for one member of the population). Indeed, as far as I can tell, it’s a form of prioritarianism, in that it ranks outcomes by way of a sum of utilities which are discounted by the application of a concave function (you preserve the ranking of outcomes if you transform the compromise utility function by a monotone increasing function, and in this case we can first raise it to the mth power, and then take logs, and the result will be the sum of log utilities. And since log is itself a concave function this meets the criteria for prioritarianism). Anyway, the point here is not to evaluate Nash social welfare, but to derive it.
The formal result is proved in the Pettigrew paper, as a corollary to a very general theorem. Under the current interpretation that theorem also has the link between squared Euclidean distance and utilitarianism of the previous post as another special case. However, it might be helpful to see how the result falls out of elementary minimization (it was helpful for me to work through it, anyway, so I’m going to inflict it on you). So we start with the following characterization, where A is the set of agents whose utilities we are given:

To find this we need to find X which makes this sum minimal (P being the set of n propositions over which utilities are defined, and A being the set of m agents):
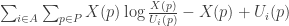
Rearrange as a sum over p:

Since we can assign each X(p) independently of the others, we minimize this sum by minimizing each summand. Fixing p, and writing 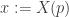

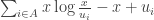
We do this by differentiating and setting the result to zero. The result of differentiating (once you remember the product rule and that differentiating logs gives you a reciprocal) is:
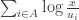
But a sum of logs is the log of the product, and so the condition for minimization is:
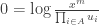
Taking exponentials we get:

That is:
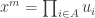
Unwinding the definitions of the constants and variables gets us the geometrical mean/Nash social welfare function as promised.
So that’s really neat! But there’s another question to ask here (also answered in the Pettigrew paper). What happens if we minimize sum total distance, not from the compromise utility to each of the components, but from the components to the compromise? Since GKL distance/divergence is not symmetric, this could give us something different. So let’s try it. We swap the positions of the constant and variables in the sums above, and the task becomes to minimize the following:

When we come to minimize this by differentiating, we no longer have a product of functions in x to differentiate with respect to x. That makes the job easier, and ends up with us with the constraint:

Rearranging we get:

and we’re back to the utilitarian compromise proposal again! (That is, this distance-minimizing compromise delivers the arithmetical mean rather than the geometrical mean of the components).
Stepping back: what we’ve seen is that if you want to do distance-minimization (similarity-maximization, minimal-mutilation) compromise on cardinal utilities then the precise way distance you choose really matters. Go for squared euclidean distance and you get utilitarianism dropping out. Go for the log distance of the GKL, and you get either utilitarianism or the Nash social welfare rule dropping out, depending on the “direction” in which you calculate the distances. These results are the direct analogues of results that Pettigrew gives for belief-pooling. If we assume that the way of measuring similarity/distance for beliefs and utilities should be the same (as I did at the start of this series of posts) then we may get traction on social welfare functions through studying what is reasonable in the belief pooling setting (or indeed, vice versa).
