
In Simulating Minds Alvin Goldman develops his account of “mindreading”, i.e. the conditions under which we humans attribute to one another beliefs and desires (and feelings, high-level decisions, actions, perceivings, and so on). This isn’t an epistemological theory, of how our beliefs about other minds are justified, but an empirical theory of how we in fact go about the task. Accordingly, evidence from neuroscience, cognitive science and psychology looms large.
Goldman sees himself as defending a “simulation theory”, according to which the central mechanism for mindreading others is one where we use our own processes for forming beliefs and desires (on the basis of evidential inputs) or forming decisions (on the basis of beliefs of desires). The idea is that we have the capacity to deploy these processes “offline”, inputting pretend-evidence into our usual belief-and-desire forming processes, and extracting pretend-belief and pretend-desire. Or, indeed, inputting pretend-belief and pretend-desire into our normal decision-making procedures and extracting pretend-decisions. According to Goodman, a paradigmatic belief attribution might first, identify the presumed evidence of our target; second, use the simulation routine to generate pretend-belief that p, third, use an introspection/classification/attribution routine, with the overall upshot of that we form the belief that our target believes that p.
Goldman thinks of this only as a description of our “fundamental and default” mode of mindreading. Presumably the beliefs that are generated by the three-step procedure will, in the usual course of events, be brought into contact with other beliefs that we might have about the target. For example, we might have been told by a reliable source that the target definitely did not believe that p, or we might have general inductive evidence that people don’t believe that p. We might acquire information that the target is a spy who’s aiming to fool us into believing that p. Acknowledging that we are sensitive to these kind of rebutting or undercutting defeaters are quite consistent with Goldman’s theory. The point, I take it, of his describing the simulation mechanism as “default” is to allow its outputs to be weighed against all sorts of other evidence which might lead to us not ending up with the beliefs that simulation procedures direct us to. Goldman can also acknowledge that we sometimes form beliefs about others’ mental states through testimony or induction, without any role for simulation. The point, I take it, of his describing simulation-based mind-reading as “fundamental” is to acknowledge that we form beliefs about others mental states by induction and testimony, but to categorize these as subordinate to the mindreading method he is describing. All this seems pretty commonsensical–a basic but compelling foundationalist thought is that if we trace back the chains of testimony and induction, on pain of regress, we need some non-inductive or non-testimonial way of forming beliefs about others’ beliefs. Mindreading Goldman-style is a natural candidate.
A pure form of simulationism would claim that it can produce attributions of belief and desire to a target quite independently any prior views the attributer has about the target’s beliefs and desires. Pure simulationism is quite compatible with the kind of story just told about the need to integrate the outputs of simulation with prior views about the target’s psychology, but it would see that as strictly optional. But Goldman doesn’t endorse pure simulationism. Indeed, there are a couple of places where he implies that prior beliefs about the target’s psychology (either specific or in the form of generics that cover all targets) are required in order to implement simulation. The central example of this involves mindreading by retrodiction. Suppose the information we have about a target includes how they behave. We want to let this inform our opinion about what their beliefs and desires are. The interpreter has at their disposal their decision-making process, which takes in beliefs and desires and choice situations and spits out decisions. But that mechanism runs in the wrong direction, for the present interpretive problem–one can’t directly feed in pretended-decisions and get out pretended-beliefs and desires. Goldman conjectures that the simulationist instead proceed by a process of “generate and test”. We start from a hypothesis about what the target believes/desires, convert that into pretend-believes and desires which are fed, offline, into our own decision making procedure, resulting in pretend-decisions. If this matches the observed decisions, the hypothesis has passed the test and can be classified and attributed to the target. If not, we need to loop back to generate a new hypothesis. This generate-and-test loop for retrodictive mindreading involves simulation, but the “generation” (and regeneration upon failure) is not explained by simulative means. Some other explanation is owing about how we generate the hypothesis. And Goldman suggests that here we will appeal to our prior beliefs about what the target’s psychology is likely to be. If prior beliefs about target psychology are essential to retrodictive mindreading, as this suggests, then Goldman’s account is not pure simulationism. Goldman acknowledges and embraces this—he thinks that what we will end up is a compound story that involves elements of theorizing as well as simulating within the “fundamental and default” story about how we attribute higher mental states to others. (This concession generates some dialetical vulnerabilities for Goldman’s wider project, as Carruthers points out in his NDPR review of Goldman’s book.)
As I see it, the significant issue here is not that we *sometimes* use prior knowledge about others to generate hypotheses about their mental states which are fed into the generate-and-test simulation routine. That’s as unproblematic as the idea that the outputs of simulation routines need to be integrated into prior opinions about others, before they are ultimately endorsed. What’s significant is that it is looking like such prior knowledge is, for all Goldman says, always required for simulationist mindreading, to generate the hypotheses for retrodictive testing. And that means that some other method of arriving at beliefs about others’ psychology needs to be co-fundamental with the simulationist method, on pain of regress.
I want to describe a purer simulationism. Crucial to this is to think about the way the predictive and retrodictive mindreading combine. In essence, the idea will be that predictive mindreading can generate the hypotheses that are tested by retrodiction. Let’s see how that might work.
Rather than assume we *either* have information about a target’s evidential situation, or about their behaviour, let’s suppose (more realistically) that we have some information about both. Given this, here’s a doubly simulationist proposal. First, identify the target’s evidence, and run a simulation with those as pretend-outputs, to arrive at an initial set of “pretend-beliefs and desires”. This generates an initial “anchor” hypothesis about what the target’s psychology is like. But we haven’t yet brought to bear what is known about their behaviour. So we test the anchor hypothesis by feeding it into our decision-making process, arriving at pretend-decisions/behaviour. In the good case, the pretend-decisions and their behavioural signature match the behaviour that is observed, and we’ve just run a complete double cycle of simulationist mindreading, and are ready to classify and attribute the attitudes to the target.
In the bad case, though, there’s a mismatch between reality and the simulated decisions generated by the anchor hypothesis. In this case, we need to revise the hypothesis and try again. The pure simulationist at this point can conjecture that there is a fixed search space—an list of modifications to try, in order to generate a revised hypothesis. Picturesequely, we can imagine a space of possible interpretations, ordered by similarity to one another. The anchor interpretation generated by simulating the target’s reaction to evidence gives a starting point to be fed into the simulation-test-procedure to see if the decisions it predicts match those observed. If that fails to pass the test, then we move to try a sphere of closest interpretations to the anchor, and try those. If that fails, we move yet further out, and so on—until we run out of patience and give up. This is a hypothesis generating procedure that does not presuppose any prior information about the target’s psychology or the psychologies of agents in general, but only a measure of similarity between interpretations that defines a search method.
What would be the upshot of this combined way of mindreading? When starting with information about both evidential input and behavioural output of a target, we’d end up attributing that belief/desire psychology which is most similar (among psychologies that, under simulation, match the observed behaviour) to the belief/desire psychology produced by simulation of the evidence.
Just as before, this candidate psychological attribution will be tempered (rebutted/undercut/modified) by anything we happen to know about the target, and various stages in the pure form of the mindreading method can substituted by opinions we happen to hold. But even granted all this, what we have, I claim, is a possible pure simulationist routine for mindreading, one that could in principle be run entirely independently of prior views about what beliefs and desires the target has. It could, indeed, be the way we form the initial beliefs that are grist to the mill of induction and IBE by which we form psychological generalizations of that kind, within a foundationalist epistemology.
This last claim requires that prior opinion about beliefs/desires of others isn’t presupposed anywhere else in the method. Carruthers in his review of Goldman suggests that there’s another place where prior opinion matters—even predictive simulation requires we identify what the target’s evidence is, in order that this converted to pretend-evidence to be fed into our belief-forming mechanisms. That worry doesn’t seem so serious to me. As ever, the pure simulationist can concede it’s possible for prior beliefs to determine what we should take the pretend-evidence to be, to feed into the simulationist mindreading. But Goldman also defends “lower level”, automatic processes of mindreading, whereby visual information the attributer has about a target involuntarily triggers a “mirroring” within the attributer of the target’s perceptual processes. So this seems like a route entirely independent of beliefs about evidence, by which an Goldman style simulationist interpreter can identify the evidential situation of a subject, and then, by secondary “higher level” simulation, generate beliefs about what propositional attitudes they possess. The same goes for the identification of behaviour.
A second place where prior opinion might matter is the following. Goldman appeals to a distinction between those beliefs/desires of the attributer that are ‘quarantined’ (not used as auxiliary premises in simulating belief-formation/decisions) and those beliefs/desires that are not quarantined. What that distinction is, or should be, and whether *that* depends on prior opinion about targets, is I think a central question for the Goldman-style simulationist. And it’s another possible loci for simulation being infected by opinion. If the idea is that we quarantine those attitudes of ours we know to be idiosyncratic, then knowledge of how our psychological compares to those of others would be central to the operation of simulation itself. I think this, too, can be resisted, and a different story about quarantine given, but that is a matter for another time.
There are two things I take away from this discussion. The first is that it’s at least open to Goldman to develop a pure form of simulationism on which simulation is the *only* fundamental/default mindreading process, albeit one that only be operates in a “pure” way in the idealized limit. The second thing I take away from the discussion is the recipe that simulationism predicts, in that idealized limit. That is: in the ideal limit we attribute the behaviour-simulating interpretation which is most similar to the anchor interpretation simulated by the target’s evidence. That last bit of information is the sort of thing that is crucial to *my* larger project right now.
 if p is true,
if p is true, 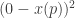 if p is false (to get a measure of accuracy, subtract inaccuracy from 1). For an agent whose own credal state is a, it’s a familiar piece of bookwork to show this implies that the epistemic utility of a credal state x(p) is
if p is false (to get a measure of accuracy, subtract inaccuracy from 1). For an agent whose own credal state is a, it’s a familiar piece of bookwork to show this implies that the epistemic utility of a credal state x(p) is  —one minus the square euclidean distance between the agent’s own a(p) and the target credence x(p). From now on, I’ll drop the indexing to p, since only one proposition will be at issue throughout.
—one minus the square euclidean distance between the agent’s own a(p) and the target credence x(p). From now on, I’ll drop the indexing to p, since only one proposition will be at issue throughout.  for the epistemic utility for agent A (who has credal state a). So forming the specific team credence x will be worthwhile from A’s perspective if and only if the epistemic utility (expected accuracy) of forming that team credence is greater than the default, i.e. iff
for the epistemic utility for agent A (who has credal state a). So forming the specific team credence x will be worthwhile from A’s perspective if and only if the epistemic utility (expected accuracy) of forming that team credence is greater than the default, i.e. iff 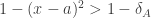 . Now, we may be able to find a possible credal state $d_a$ which the agent ranks equally with the default credal state,
. Now, we may be able to find a possible credal state $d_a$ which the agent ranks equally with the default credal state,  . You can think of
. You can think of  as A’s breaking point—the credence at which it’s no longer in her epistemic interests to form a team credence, since she’s indifferent between that and the default where no team credence is formed. A little rearrangement gets us to:
as A’s breaking point—the credence at which it’s no longer in her epistemic interests to form a team credence, since she’s indifferent between that and the default where no team credence is formed. A little rearrangement gets us to:  . So really we have both an upper and lower breaking point, and within these bounds, a zone of acceptable compromises, within which a team credence will look good from that agent’s perspective.
. So really we have both an upper and lower breaking point, and within these bounds, a zone of acceptable compromises, within which a team credence will look good from that agent’s perspective. ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.  may well be outside that interval. Consider, for example, the case where an agent has credence 1 or 0 in p to start with, or a situation where not forming a team credence is a true epistemic disaster, of disutility >1. It’ll be formally convenient to still talking of breaking point credences in these cases, but that’ll just be a manner of speaking.
may well be outside that interval. Consider, for example, the case where an agent has credence 1 or 0 in p to start with, or a situation where not forming a team credence is a true epistemic disaster, of disutility >1. It’ll be formally convenient to still talking of breaking point credences in these cases, but that’ll just be a manner of speaking.  . That amounts to insisting that the set of open intervals
. That amounts to insisting that the set of open intervals 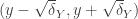 have a non-empty intersection, or equivalently, where y runs over hte team members,
have a non-empty intersection, or equivalently, where y runs over hte team members,  .
. 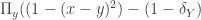 . Simplifying a touch, the latter curve becomes
. Simplifying a touch, the latter curve becomes 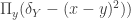 .
. ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002) . This is pretty intuitively obvious, but to argue for it formally: suppose that we have N agents with various starting credences, whose span is the interval
. This is pretty intuitively obvious, but to argue for it formally: suppose that we have N agents with various starting credences, whose span is the interval  . So looking at the curve defined by Nash’s product alone doesn’t contain all the information we need to pick the constrained maximum. I’ll come back to this at the end, but for now, I’ll ignore the issue and concentrate on finding a local maximum of the Nash curve.
. So looking at the curve defined by Nash’s product alone doesn’t contain all the information we need to pick the constrained maximum. I’ll come back to this at the end, but for now, I’ll ignore the issue and concentrate on finding a local maximum of the Nash curve.  . To see what’s going on with this quartic polynomial, consider a special simple case with a at 1 and b at 0, and both offsets at zero. That gives
. To see what’s going on with this quartic polynomial, consider a special simple case with a at 1 and b at 0, and both offsets at zero. That gives  , which I’ve sketched for you (as with the other images that follow) using wolframalpha:
, which I’ve sketched for you (as with the other images that follow) using wolframalpha:
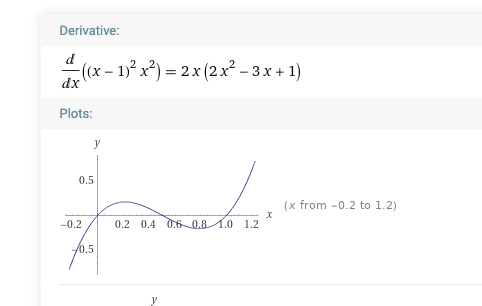
 . The cubic has three roots: 0 and 1 (those are the minimum points of the original quartic curve) and 0.5.
. The cubic has three roots: 0 and 1 (those are the minimum points of the original quartic curve) and 0.5. 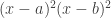 ,
, 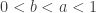 then you get curves that look like distorted versions of the above, but with roots of the original curve at a and b, and a local maximum at
then you get curves that look like distorted versions of the above, but with roots of the original curve at a and b, and a local maximum at  —the linear average of the starting credences.
—the linear average of the starting credences.  , which translates to both agents having a null zone of compromise (in terms of breaking points: the breaking point credence for each agent is the point at which they’re at). There’s no non-trivial bargaining problem at all here! So that there’s a local maximum of the curve at the linear average doesn’t tell us anything of interest. Bother.
, which translates to both agents having a null zone of compromise (in terms of breaking points: the breaking point credence for each agent is the point at which they’re at). There’s no non-trivial bargaining problem at all here! So that there’s a local maximum of the curve at the linear average doesn’t tell us anything of interest. Bother.  . Multiplying this out we have:
. Multiplying this out we have:  . Differentiating this and setting the result to zero we have
. Differentiating this and setting the result to zero we have  . This is equivalent to finding the intersection of the cubic sketched above and the linear curve
. This is equivalent to finding the intersection of the cubic sketched above and the linear curve 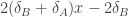 . To illustrate, here’s a sketch of what happens when both parameters are set to 1. The intersection, and so the local maximum of the original curve, is the average of the two credences, at 0.5:
. To illustrate, here’s a sketch of what happens when both parameters are set to 1. The intersection, and so the local maximum of the original curve, is the average of the two credences, at 0.5: 
 but
but  . Note that the intersection is now below the linear average of the two starting credences (that makes sense: the parameters tell us that A, with full credence, is more distant from her breaking point than B, who has zero credence—or equivalently, failing to agree a team credence is in relative terms better for B than for A. So A is in the weaker bargaining position and the solution is more in line with B’s credence):
. Note that the intersection is now below the linear average of the two starting credences (that makes sense: the parameters tell us that A, with full credence, is more distant from her breaking point than B, who has zero credence—or equivalently, failing to agree a team credence is in relative terms better for B than for A. So A is in the weaker bargaining position and the solution is more in line with B’s credence):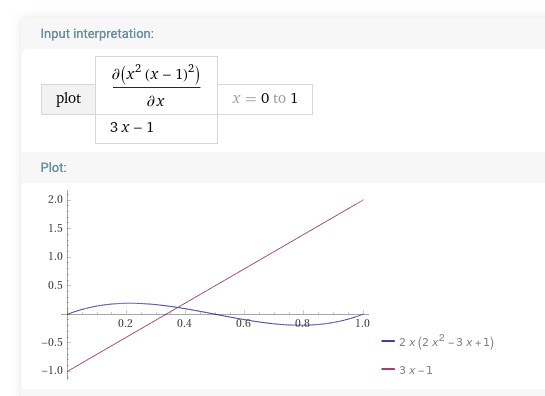
![[b,a]](https://s0.wp.com/latex.php?latex=%5Bb%2Ca%5D&bg=ffffff&fg=333333&s=0&c=20201002) . So under what conditions is it in the top half,
. So under what conditions is it in the top half, ![(\frac{a+b}{2}, a]](https://s0.wp.com/latex.php?latex=%28%5Cfrac%7Ba%2Bb%7D%7B2%7D%2C+a%5D&bg=ffffff&fg=333333&s=0&c=20201002) ? At the bottom half
? At the bottom half  ? And at the midpoint
? And at the midpoint  . Second, differentiate the quartic and set the result to zero. This gives us
. Second, differentiate the quartic and set the result to zero. This gives us 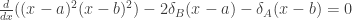 . This is equivalent to finding the intersection of the cubic
. This is equivalent to finding the intersection of the cubic  and the linear curve
and the linear curve  . The former, recall, is like a squished version of the the earlier cubic, with roots at
. The former, recall, is like a squished version of the the earlier cubic, with roots at  –the middle root corresponding to the local maximum.
–the middle root corresponding to the local maximum. 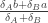 . That will be within the interval only if
. That will be within the interval only if  , which is to say:
, which is to say:  . Multiply out, simplify while remembering we were assuming a>b, and you will find this is equivalent to:
. Multiply out, simplify while remembering we were assuming a>b, and you will find this is equivalent to: 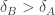 . (Interpretation: the epistemic utility of no team credence is higher for A (at
. (Interpretation: the epistemic utility of no team credence is higher for A (at  )).
)).  . And the two curves intersect at
. And the two curves intersect at 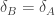 . And given the curves intersect somewhere in the interval [b,a], and the three conditions are mutually exclusive, we can now strengthen these two conditionals to biconditionals.
. And given the curves intersect somewhere in the interval [b,a], and the three conditions are mutually exclusive, we can now strengthen these two conditionals to biconditionals. 
 . In the special case where
. In the special case where  , that means
, that means  . The compromise zone is maximal, i.e. the whole of
. The compromise zone is maximal, i.e. the whole of  .
. 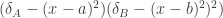 has a “W” shaped curve. For very negative values of x, then both
has a “W” shaped curve. For very negative values of x, then both  and $(\delta_B-(x-b)^2)^2)$ are large and negative, and so their product is large and positive. For very positive values of x, both are large and again negative, so their product is large and again positive. If all roots are real, then moving from left to right, as x approaches a we get an interval where
and $(\delta_B-(x-b)^2)^2)$ are large and negative, and so their product is large and positive. For very positive values of x, both are large and again negative, so their product is large and again positive. If all roots are real, then moving from left to right, as x approaches a we get an interval where  will do. Likewise, it is necessary for the compromise zone to be maximal that
will do. Likewise, it is necessary for the compromise zone to be maximal that 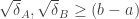 , and then there is a more complex condition involving c and
, and then there is a more complex condition involving c and  suffices, but e.g. if c is the midpoint then a smaller
suffices, but e.g. if c is the midpoint then a smaller 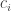 such that they’d be indifferent between having that as the team credence, and giving up altogether. In accordance with accuracy-first methodology, we’ll assume that credences are better and worse by the lights of an agent exactly in proportion to how accurate the agent expects that credence to be. The expected accuracy of
such that they’d be indifferent between having that as the team credence, and giving up altogether. In accordance with accuracy-first methodology, we’ll assume that credences are better and worse by the lights of an agent exactly in proportion to how accurate the agent expects that credence to be. The expected accuracy of 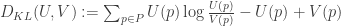
 that emerges from a set of m utility functions
that emerges from a set of m utility functions  is the geometrical mean:
is the geometrical mean: .
. 
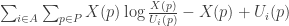

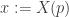 and
and  , our task now is to find the value of u which minimizes the following:
, our task now is to find the value of u which minimizes the following: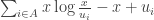
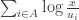
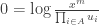

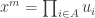



 is the finite set of n propositions at issue, we characterize similarity like this:
is the finite set of n propositions at issue, we characterize similarity like this: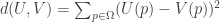
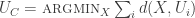


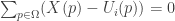

 such that for each proposition p,
such that for each proposition p,  (see Gaertner ch7). Now, it seems like the squared euclidean similarity measure doesn’t jive with this picture at all. After all, if we measure the squared Euclidean distance between U and V that differ by a constant, as above, we get:
(see Gaertner ch7). Now, it seems like the squared euclidean similarity measure doesn’t jive with this picture at all. After all, if we measure the squared Euclidean distance between U and V that differ by a constant, as above, we get:
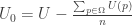 .
. 
 .) You find the minimum element in this set of distances (the closest the two equivalence classes come to each other) by differentiating with respect to gamma and setting the result to zero. That is:
.) You find the minimum element in this set of distances (the closest the two equivalence classes come to each other) by differentiating with respect to gamma and setting the result to zero. That is: 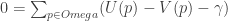 ,
, 
 and
and 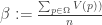 , and we have defined two level boosted variants of the original U and V which minimize the distance between the classes of which they are representatives (in the square-euclidean sense). But note these level boosted variants are just
, and we have defined two level boosted variants of the original U and V which minimize the distance between the classes of which they are representatives (in the square-euclidean sense). But note these level boosted variants are just  and
and 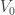 . That is: minimal distance (in the square-euclidean sense) between two equivalence classes of utility functions is achieved by looking at the squared euclidean distance between the representatives of those classes that are closest to the null utility.
. That is: minimal distance (in the square-euclidean sense) between two equivalence classes of utility functions is achieved by looking at the squared euclidean distance between the representatives of those classes that are closest to the null utility. 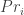 . And suppose we’re given total information about the total evidence
. And suppose we’re given total information about the total evidence  available to x (just as we were given total information about her choice-dispositions). Then we can construct an ideal posterior probability,
available to x (just as we were given total information about her choice-dispositions). Then we can construct an ideal posterior probability,  , which are the ideal doxastic attitudes to have in x’s evidential situation. Now, we can’t simply assume that x is epistemically ideal–there’s no guarantee that there’s any probability-utility pair among the agential candidates for x’s psychology whose first element matches
, which are the ideal doxastic attitudes to have in x’s evidential situation. Now, we can’t simply assume that x is epistemically ideal–there’s no guarantee that there’s any probability-utility pair among the agential candidates for x’s psychology whose first element matches 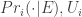 .
. 
You must be logged in to post a comment.