
To a first approximation, decision theoretic representation theorems take a bunch of information about (coherent) choices of an agent x, and spit out probability-utility pairs that (structurally) rationalize each of those choices. Call that the agential candidates for x’s psychology.
Problems arise if there are too many agential candidates for x’s psychology—if we cannot, for example, rule out hypotheses where x believes that the world beyond her immediate vicinity is all void, and where her basic desires solely concern the distribution of properties in that immediate bubble. And I’ve argued in other work that we do get bubble-and-void problems like these.
I also argued in that work that you could resolve some of the resulting underdetermination by appealing to substantive, rather than structural rationality. In particular, I said we make a person more substantively rational by representing her IBE inferences by inferences to genuinely good explanations (like the continued existence of things when they leave her immediate vicinity) than some odd bubble-and-void surrogate.
So can we get a simple model for this? One option is the following. Suppose there are some “ideal priors” that encode all the good forms of inference to the best explanation 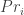


(One warning about the closeness metric we need—I think you’ll get the wrong results if this were simply a matter of measuring the point-wise similarity of attitudes. Roughly—if you can trace the doxastic differences between two belief states to a single goof that one agent made that the other didn’t, those can be similar even if there are lots of resulting divergences. And a belief state which diverged in many different unrelated ways—but where the resulting differences are less far reaching—should in the relevant sense be less similar to one of the originals than either is from each other. A candidate example: the mashed up state which agrees with both where they agree, and then where they diverge agrees with one or the other at random. So a great deal is packed into this rich closeness ordering. But also: I take it to be a familiar enough notion that is okay to use in these contexts)
So, in any case, that’s my simple model of how evidential charity can combine with decision-theoretic representation to yield the results—with the appeals to substantive rationality packed into the assumption of ideal priors, and the use of the closeness metric being another significant theoretic commitment.
I think we might want to add some further complexity, since it looks like we’ve been appealing to substantive rationality only as it applies to the epistemic side of the coin, and one might equally want to appeal to constraints of substantive rationality on utilities. So along with the ideal priors you might posit ideal “final values” (say, functions from properties of worlds to numbers, which we’d then aggregate—e.g. sum—to determine the ideal utilities to assign to a world). By pairing that with the ideal posterior probability we get an ideal probability-utility pair, relative to the agents evidence (I’m assuming that evidence doesn’t impact the agent’s final values—if it does in a systematic way, then that can be built into this model). Now, given an overall measure of closeness between arbitrary probability-utility pairs (rather than simply between probability pairs) we can replicate the earlier proposal in a more general form: the the evidential-and-agential candidates for x’s psychology will be those agential candidates which are maximally close to the pair 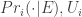
(As before, this measure of closeness between psychologies will have to do a lot of work. In this case, it’ll have to accommodate rationally permissible idiosyncratic variation in utilities. Alternatively—and this is possible either for the ideal priors or the ideal final values/utilities—we could start from a set of ideal priors and ideal final values, and do something a bit more complex with the selection mechanism—e.g. pick out the member(s) of the set of ideal psychologies and the set of agential candidates psychologies which are closest to one another, attribute the latter to agent as their actual psychology, and the former as the proper idealization of their psychology. This allows different agents to be associated systematically with different ideal psychologies.
This is a description of interpretation-selection that relies heavily on substantive rationality. It is an implementation of the idea that when interpreting others we maximize how favourable a psychology we give them—this maximizing thought is witnessed in the story above by the role played by closeness to an ideal psychology.
I also talked in previous posts about a different kind of interpretation-selection. This is interpretation selection that maximizes, not objective favourability, but similarity to the psychology of the interpreter themself. We can use a variant of the simple model to articulate this. Rather than starting with ideal priors, we let the subscript “i” above indicate that we are working with the priors of the flesh and blood interpreter. We start with this prior, and feed it x’s evidence, in order to get a posterior probability tailored to x’s evidential situation (though processed in the way the interpreter would do). Likewise, rather than working with ideal final values, we start from the final values of the flesh and blood interpreter (if they regard some of their values as idiosyncratic, perhaps this characterizes a space of interpreter-sanctioned final values—that’s formally like allowing the set of ideal final values in the earlier implementation). From that point on, however, interpretation selection is exactly as before. The selected interpretation of x is that one among the agential candidates to be her psychology that is closest the interpreter’s psychology as adjusted and tailored to x’s evidential situation. This is exactly the same story as before, except with the interpreter’s psychology playing the role of the ideal.
Neither of these are yet in a form in which they could be a principle of charity implementable by a flesh and blood agent themselves (neither are principles of epistemic charity). They presuppose, in particular, that one has total access to x’s choice dispositions, and to her total evidence. In general, one will only have partial information at best about each. One way to start to turn it into a simple model of epistemic charity would be to think of there being a set of possible choice-dispositions that for all we flesh-and-blood interpreters know, could be the choice-dispositions of x. Likewise for her possible evidential states. But relative to each set of complete choice-dispositions and evidence pair characterizing our target x, either one of the stories above could be run, picking out a “selecting interpretation” for x in that epistemic possibility (if there’s a credal weighting given to each choice-evidence pair, the interpretation inherits that credal weighting).
In order for a flesh and blood interpreter—even one with insane computational powers—to implement the above, they would need to have knowledge of the starting psychologies on the basis of which the underdetermination is to be resolved (also the ability to reliably judge closeness). If the starting psychology is the interpreter’s own psychology, as on the second, similarity-maximizing reading of the story, then what we need to act is massive amounts of introspection. If the starting point is the an ideal psychology, however, then in order for the recipe to be usable by a flesh and blood interpreter with limited information, they would need to be aware of what the ideal was—what ideal priors are, and what the ideal final values are. If part of the point is to model interpretation by agents who are flawed in the sense of having non-ideal priors and final values (somewhat epistemically biased, somewhat immoral agents) then this is a interesting but problematic thing to credit them with. If the are aware of the right priors, what excuse do they have for the wrong ones? If they know the right final values, why aren’t they valuing things that way?
An account—even an account with this level of abstraction built in—should I think allow for uncertainty and false belief about what the ideal priors and final values are, among the flesh and blood agents who are deploying epistemic charity. So as well as giving our interpreter a set of epistemic possibilities for x’s evidence and choices, we will add in a set of epistemic possibilities for what the ideal priors and values in fact are. But the story is just the same: for any quadruple of x’s evidence, x’s choices, the ideal priors and ideal values, we run the story as given to select an interpretation. And credence distributions on an interpreter’s part across these valuations will be inherited as a credence distribution across the interpretations.
With that as our model of epistemic charity, we can then identify two ways of understanding how an “ideal” interpreter would interpret x, within the similarity-maximization story.
The first idealized similarity-maximization model says that the ideal interpreter knows the total facts of an interpreter, y’s psychology, and also total information about x’s evidence and choices. You feed all that information into the story as given, and you get one kind of result for what the ideal interpretion of x is (one that is relative to y, and in particular, y’s priors and values).
The second idealized similarity-maximization model says that the ideal interpeter knows the total facts about her own psychology, as well as total informationa bout x’s evidence and choices. The ideal interpreter is assumed to have the ideal priors and values, and so maximizing similarity to that psychology just is to maximizing closeness to the ideal. So if we feed all this information into the story as given, and we get a characterization of the ideal interpretation of x that is essentially the same as the favourability-maximization model that I started with.
Ok, so this isn’t yet to argue for any of these models as the best way to go. But if the models are good models of the ways that charity would work, then they might help to fix ideas and explore the relationships among them.

I’ll say before anything else: I’ll be picking fights with specific bits of the proposal, but I’m not sure whether the bits I’m picking fights with are reflective of your more considered thoughts on the matter or whether they’re just the consequence of simplifications.
Start with this: “decision theoretic representation theorems take a bunch of information about (coherent) choices of an agent x, and spit out probability-utility pairs that (structurally) rationalize each of those choices. Call that the agential candidates for x’s psychology”.
I want to get clear first on exactly what it is that’s being rationalised and how that rationalisation is working. On the interpretation of representation theorems that you’re referring to here, what’s being taken as “input” is an ordering over acts, ≽, gambles (whatever), which represents an agent’s choice dispositions at a time. So we’re taking that as our first input to the process of interpretation, and “the candidates” for x’s psychology at a time are all probability-utility pairs (P,U) that rationalise those choice dispositions at that time. We know that choice dispositions in this sense underdetermine probability-utility pairs at least in some cases, so we need a way to filter between candidate psychologies. Ignoring substantive rationality for utilities, the main proposal is then to select that candidate (P,U) that rationalises ≽ and is such that P^E comes closest to Pi^E, where Pi is the ideal prior, E is the agent’s total evidence up to that point in time, and P^E is P conditionalized on E.
Now what strikes me as problematic in this is that the ‘correct’ interpretation of an agent at time t is going to be a function of their choice dispositions at t plus their evidence up to t. Now that, I think, is going to lead to some strange possible cases where you get what looks like a nice rationalisation of the agent for each individual time, but over time the agent looks very inconsistent and irrational. All we need to do is imagine an agent who at t has choice dispositions ≽ and evidence E that are jointly rationalised by (P,U), then they get a little more evidence E* but their choice dispositions alter such that the proposal picks out candidate (P*,U*), where P* is not much like P^E* and U ≠ U*. So we’ll be able to come up with cases where the agent is simultaneously represented as a fantastically consistent conditionalizer for each moment in time given their evidence up to that time, but over time cannot conditionalize to save their life!
I think we can solve this, by the way, if we adopt something more closer to (what I take to be) the kind of functionalism Lewis was putting forward. The principle of Fit for schemes of interpretation takes into account not only how (P,U) at a time relate to choices at that time and evidence up to that time, but also how (P,U) relates to earlier and later moments. So, e.g., consistency over time is built in as something that improves fitness. But I don’t think you have to be a functionalist in order to incorporate that kind of insight.
So I guess the main question I have is: what about interpreting an agent not at a time, but over time? This would require re-working how we think about, e.g., choice dispositions, and likewise the kind of thing that we’ll be saying should be more or less (substantively) rational will not be (P,U) pairs, but sequences of (P,U) pairs. (Or even better, we can incorporate not only how the agent does change over time but also how they would have changed if they had such-and-such evidence instead, by considering functions from probability-utility pairs plus evidence to new probability-utility pairs.)