
In connection to this paper, I’ve been thinking some more about what grounds we might have for saying substantive things about how “scoring rules” should behave.
Quick background. Scoring rules rank either credences in a single proposition, or whole credence functions (depending on your choice of poison) against the actual truth values. For now, let’s concentrate on the single-proposition case. In the context we’re interested in, they’re meant to measure “how (in)accurate” the credences are. I’ll assume that scoring rules take the form s(x,y), where x is the credence, and y the truth value of the salient proposition (1 for truth, 0 for falsity). You’d naturally expect a minimal constraint to be:
(Minimal 1) s(1,1)=s(0,0)=1; s(0,1)=s(1,0)=0.
(Minimal 2) s is a monotone increasing function in x when y=1. s is a monotone decreasing function in x when y=0.
Basically, this just says that credences 1 and 0 are maximally and minimally accurate, and you never decrease in accuracy by moving closer to the truth value.
But to make arguments from scoring rules for probabilism run, we need a lot more structure. Where do we get it from?
There’s a prior question: what’s the nature of a scoring rule in the first place? There’re a couple of thoughts to have here. One is that scoring rules are *preferences* of agents. Different agents can have different scoring rules, and the relevant preference-ordering aims to capture the subjective value the agent attaches to having *accurate* credences.
Now, various hedges are needed at this point. Maybe having certain credences make you feel warm and fuzzy, and you prefer to have those feelings no matter what. We need to distill that stuff out. Moreover, maybe you value having particular credences in certain situations because of their instrumental value—e.g. enabling you indirectly to get lots of warm fuzzy stuff. One strong thesis about scoring rules is that they give the *intrinsic* value that the agent attaches to a certain credence/truth value state of affairs—her preferences given that alethic accuracy is all she cares about. However tricky the details of this are to spell out, the general story about what the scoring rule aim to describe is pretty clear—part of the preferences of individual agents.
A different kind of view would have it that the scoring rule describes a more objective beast: facts about which credences are better than which others (as far as accuracy goes). Presumably, if there are such betterness facts, this’ll provide a standard for assessing people’s alethic preferences in the first sense.
On either view, the trick will be to justify the claim that the scoring rule have certain formal features X. Then one appeals to a formal argument that shows that for every incoherent credence c, there’s a coherent credence d which is more accurate (by the lights of the scoring rule) than c no matter what the actual truth values are—supposing only that the scoring rule has feature X. Being “accuracy dominated” in this way is supposed to be an epistemic flaw (at least a pro tanto one). [I’m going to leave discussion of how *that* goes for another time]
Ok. But how are we going to justify features of scoring, other than the minimal constraints above? Well, Joyce (1998) proceeds by drawing out what he regards as unpleasant consequences of denying a series of formal constraints on the scoring rule. Though it’s not *immediately obvious* that to be a “measure of accuracy” scoring rules need to do more than satisfy *minimal*, you may be convinced by the cases that Joyce makes. But what *kind* of case does he make? One thought is that it’s a kind of conceptual analysis. We have the notion of accuracy, and when we think carefully through what can happen if a measure doesn’t have feature X, we see that whatever its other merits, it wouldn’t be a decent way to measure anything deserving the name *accuracy*.
Whether or not Joyce’s considerations are meant to be taken this way (I rather suspect not), it’s at least a very clean project to engage in. Take scoring rules to be preferences. Then a set of preferences that didn’t have the formal features just wouldn’t be preferences solely about accuracy—as was the original intention. Or take an objective betterness ordering. If it’s evaluating credence/world pairs on grounds of accuracy, again (if the conceptual analysis of accuracy was successful) it better have the features X, otherwise it’s just not going to deserve the name.
But maybe we can’t get all the features we need through something like conceptual analysis. One of Joyce’s features—convexity—seems to be something like a principle of epistemic conservativism (that’s the way he has recently presented it). It doesn’t seem that people would be conceptually confused if they took their alethic preferences didn’t violate this principle. Where would this leave us?
If we’re thinking of the scoring rule as an objective betterness relation, then there seems plenty of room for thinking that the *real facts* about accuracy encode convexity, even if one can coherently doubt that this is so (ok, so I’m setting aside open-question arguments here, but I was never terribly impressed by them). And conceptual analysis is not the only route to justifying claims that the one true scoring rule has such a feature. Here’s one alternative. It turns out that a certain scoring rule—the Brier score—meets all Joyce’s conditions and more besides. And it’s a very simple, very well behaved scoring rule, that generalizes very nicely in all sorts of ways (Joyce (2009) talks about quite a few nice features of it in the section “homage to the Brier score”). It’s not crazy to think that, among parties agreed that there is some “objective accuracy” scoring rule out there to be described, considerations of simplicity, unity, integration and other holistic merits might support the view that the One True measure of (in)accuracy is given by the Brier score.
But this won’t sound terribly good if you think that scoring rules describe individual preferences, rather than an objective feature that norms those preferences. Why should theoretical unification and whatnot give us information about the idiosyncracies of what people happen to prefer? If we give up on the line that it’s just conceptually impossible for there to be “alethic preferences” that fail to satisfy conditions X, then why can’t someone—call him Tommy—just happen to have X-violating alethic preferences? Tommy’s “scoring rule” then just can’t be used in a vindication of probabilism. I don’t see how the kind of holistic considerations just mentioned can be made relevant.
But maybe we could do something with this (inspired by some discussion in Gibbard (2008), though in a very different setting). Perhaps alethic preferences only need to satisfy the minimal constraints above, to deserve the name. But even if its *possible* to have alethic preferences with all sorts of formal properties, it might be unwise to do so. Maybe things go epistemically badly, e.g. if they’re not appropriately conservative because of their scoring rule (for an illustration, perhaps the scoring rule is just the linear one: s(x,y) is the absolute difference of x and y. This scoring rule motivates extremeism in credences: when c(p)>0.5, you minimize expected inaccuracy by moving your credence to 1. But someone who does that doesn’t seem to be functioning very well, epistemically speaking). Maybe things go prudentially badly, unless their alethic values have a certain form. So, without arguing that it’s analytic of “alethic preference”, we provide arguments that the wise will have alethic preferences that meet conditions X.
If so, it looks to me like we’ve got an indirect route to probabilism. People with sensible alethic preferences will be subject to the Joycean argument—they’ll be epistemically irrational if they don’t conform to the axioms of proability. And while people with unwise alethic preferences aren’t irrational in failing to be probabilists, they’re in a bad situation anyway, and (prudentially or epistemically) you don’t want to be one of them.It’s not that we have a prudential justification of probabilism. It’s that there are (perhaps prudential) reasons to be the kind of person such that its then epistemically irrational to fail to be a probabilist.
Though on this strategy, prudential/pragmatic considerations are coming into play, they’re not obviously as problematic as in e.g. traditional formulations of Dutch book arguments. For there, the thought was that if you fail to be a probabilist, you’re guaranteed to lose money. So, if you like money, be a probabilist! Here the justification is of the form: your view about the value of truth and accuracy is such-and-such. But you’d be failing to live up to your own preferences unless you are a probabilist. And it’s at a “second order” level, where we explain why it’s sensible to value truth and accuracy in the kind of way that enables the argument to go through, that we appeal to prudential considerations.
Having said all that, I still feel that the case is cleanest for someone thinking of the scoring argument as based on objective betterness. Moreover, there’s a final kind of consideration that can be put forward there, which I can’t see how to replicate on the preference-based version. It turns on what we’re trying to provide in giving a “justification of probabilism”. Is the audience one of sympathetic folk, already willing to grant that violations of probability axioms are pro tanto bad, and simply wanting it explained why this is the case (NB: the pragmatic nature of the Dutch Book argument makes it as unsatisfying for such folk as it is for anyone else). Or is the audience one of hostile people, with their own favoured non-probabilistic norms (maybe people who believe in Dempster-Shafer theory of evidence)? Or the audience people who are suitably agnostic, initially?
This makes quite a big difference. For suppose the task was to explain to the sympathetic folk what grounds the normativity of the probability axioms. Then we can take as a starting point, that one (pro tanto) ought not to violate the probability axioms. We can show how objective betterness, if it has the right form, would explain this. We can show that an elegant scoring rule like the Brier score would have the right form, and so provide the explanation. And absent competitors, it looks like we’ve got all the ingrediants for a decent inference-to-the-best-explanation for the Brier Score seen as the best candidate for measuring objective (in)accuracy.
Of course, this would cut very little ice with the hostile crowd, who’d be more inclined to tollens away from the Brier score. But even they should appreciate the virtues of being presented with a package deal, with probabilism plus an accuracy/Brier based explanation of what kind of normative force the probability axioms have. If this genuinely enhances the theoretical appeal of probabilism (which I think it does) then the hostile crowd should feel a certain pressure to try to replicate the success—if only to try to win over the neutral.
Of course, the sense in which we have a “justification” of probabilism is very much less than if we could do all the work of underpinning a dominance argument by conceptual analysis, or even pointing to holistic virtues of the needed features. It’s more on the lines of explaining the probabilist point of view, than persuading others to adopt it. But that’s far from nothing.
And even if we only get this, we’ve got all we need for other projects in which I, at least, am interested. For if, studying the classical case, we can justify Brier as a measure of objective accuracy, then when we turn to generalizations of classicism—non-classical semantics of the kind I’m talking about in the paper—then we run dominance arguments that presuppose the Brier measure of inaccuracy, to argue for analogues of probabilism in the non-classical setting. And I’d be happy if the net result of that paper was the conditional: to the extent that we should be probabilists in the classical setting, we should be analogue-probabilists (in the sense I spell out in the paper) in the non-classical setting. So the modest project isn’t mere self-congratulation on the part of probabilists—it arguably commits them to a range of non-obvious generalizations of probabilism in which plenty of people should be interested.
Of course, if a stronger, more suasive case for the features X can be made, so much the better!
 Q
Q
 ‘ is read as ‘it is determinate that’:
‘ is read as ‘it is determinate that’:

 be defined to be
be defined to be 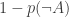 . This quantity—how little one accepts the negation of a proposition—might be thought of as the upper bound of an interval whose lower bound is the probability of A itself. So rather than describe one’s doxastic attitudes to known indeterminate A as being “zero credence” in A, one might prefer the description of them as themselves indeterminate—in a range between zero and 1.
. This quantity—how little one accepts the negation of a proposition—might be thought of as the upper bound of an interval whose lower bound is the probability of A itself. So rather than describe one’s doxastic attitudes to known indeterminate A as being “zero credence” in A, one might prefer the description of them as themselves indeterminate—in a range between zero and 1.
You must be logged in to post a comment.