
Here’s a naive view of classical semantics, but one worth investigating. According to this view, semantics is a theory that describes a function from sentences to semantic properties (truth and falsity) relative to a given possible circumstance (“worlds”). Let’s suppose it does this via a two-step method. First, it assigns to each sentence a proposition. Second, it assigns to each proposition, a function from worlds to {True, False} (“truth conditions”).
Let’s focus on the bit where propositions (at a world) are assigned truth-values. One thing that’s leaps out is that the “truth values” assigned have significance beyond semantics. For propositions, we may assume, are the objects of attitudes like belief. It’s natural to think that in some sense, one should believe what’s true, and reject what’s false. So the statuses attributed to propositions as part of the semantic theory (the part that describes the truth-conditions of propositions) are psychologically loaded, in that propositions that have one of the statuses are “to be believed” and those that have the other are “to be rejected”. The sort of normativity involved here is extremely externalistic, of course — it’s not a very interesting criticism of me that I happen to believe p, just on the basis p is false, if my evidence suggested p overwhelmingly. But the idea of an external ought here is familiar and popular. It is often reported, somewhat metaphorically, as the idea that beliefs aims at truth (for discussion, see e.g. Ralph Wedgwood on the aim of belief).
Suppose we are interested in one of the host of non-classical semantic theories that are thrown around when discussing vagueness. Let’s pick a three-valued Kleene theory, for example. On this view, we have three different semantic statuses that propositions (relative to a circumstance) are mapped to. Call them neutrally A, B and C (much of the semantic theory is then spent telling us how these abstract “statuses” are distributed around the propositions, or sentences which express the propositions). But what, if any, attitude is it appropriate to take to a proposition that has one of these statuses? If we have an answer to this question, we can say that the semantic theory is psychologically loaded (just as the familiar classical setting was).
Rarely do non-classical theorists tell us explicitly what the psychological loading of the various states are. But you might think an answer is implicit in the names they are given. Suppose that status A is called “true”, status C is called “falsity”. Then, surely, propositions that are A are to be believed, and propositions with C are to be rejected. But what of the “gaps”, the propositions that have status B, the ones that are neither true nor false? It’s rather unclear what to say; and without explicit guidance about what the theorist intends, we’re left searching for a principled generalization. One thought is that they’re at least untrue, and so are intended to have the normative role that all untrue propositions had in the classical setting—they’re to be rejected. But of course, we could equally have reasoned that, as propositions that are not false, they might be intended to have the status that all unfalse propositions have in the classical setting—they are to be accepted. Or perhaps they’re to have some intermediate status—-maybe a proposition that has B is to be half-believed (and we’d need some further details about what half-belief amounts to). One might even think (as Maudlin has recently explicitly urged) that in leaving a gap between truth and falsity, the propositions are devoid of psychological loading—that there’s nothing general to say about what attitude is appropriate to the gappy cases.
But notice that these kind of questions are at heart, exegetical—that we face them just reflects the fact that the theorist hasn’t told us enough to fix what theory is intended. The real insight here is to recognize that differences in psychological loading give rise to very different theories (at least as regards what attitudes to take to propositions), which should each be considered on their own merits.
Now, Stephen Schiffer has argued for some distinctive views about what the psychology of borderline cases should be like. As John Macfarlane and Nick Smith have recently urged, there’s a natural way of using Schiffer’s descriptions to fill out in detail one fully “psychologically loaded” degree-theoretic semantics. To recap, Schiffer distinguishes between “standard” partial beliefs (SPBs) which we can assume behave in familiar (probabilistic) ways and have their familiar functional role when there’s no vagueness or indeterminacy at issue. But then we also have special “vagueness-related” partial beliefs (VPBs) which come into play for borderline cases. Intermediate standard partial beliefs allow for uncertainty, but are “unambivalent” in the sense that when we are 50/50 over the result of a fair coin flip, we have no temptation to all-out judge that the coin will land heads. By contrast, VPBs exclude uncertainty, but generate ambivalence: when we say that Harry is smack-bang borderline bald, we are pulled to judge that he is bald, but also (conflictingly) pulled to judge that he is not bald.
Let’s suppose this gives us enough for an initial fix on the two kinds of state. The next issue is to associate them with the numbers a degree-theoretic semantics assigns to propositions (with Edgington, let’s call these numbers “verities”). Here is the proposal: a verity of 1 for p is ideally associated with (standard) certainty that p—an SPB of 1. A verity of 0 for p is ideally associated with (standard) utter rejection of p—an SPB of 0. Intermediate verities are associated with VPBs. Generally, a verity of k for p is associated with a VPB of degree k in p. [Probably, we should say for each verity, both what the ideal VPB and SPB are. This is easy enough: one should have VPBs of zero when the verity is 1 or 0; and SPB of zero for any verity other than 1.]
Now, Schiffer’s own theory doesn’t make play with all these “verities” and “ideal psychological states”. He does use various counterfactual idealizations to describe a range of “VPB*s”—so that e.g. relative to a given circumstance, we can talk about which VPB an idealized agent would take to a given proposition (though it shouldn’t be assumed that the idealization gives definitive verdicts in any but a small range of paradigmatic cases). But his main focus is not on the norms that the world imposes on psychological attitudes, but norms that concern what combinations of attitudes we may properly adopt—-requirements of “formal coherence” on partial belief.
How might a degree theory psychologically loaded with Schifferian attitudes relate to formal coherence requirements? Macfarlane and Smith, in effect, observe that something approximating Schiffer’s coherence constraints arises if we insist that the total partial belief in p (SPB+VPB) is always representable as an expectation of verity (relative to a classical credence distribution over possible situations). We might also observe that component corresponding to Schifferian SPB within this is always representable as the expectation of verity 1 (relative to the same credence). That’s suggestive, but it doesn’t do much to explain the connection between the external norms that we fed into the psychological loading, and the formal coherence norms that we’re now getting out. And what’s the “underlying credence over worlds” doing? If all the psychological loading of the semantics is doing is enabling a neat description of the coherence norms, that may have some interest, but it’s not terribly exciting—what we’d like is some kind of explanation for the norms from facts about psychological loading.
There’s a much more profound way of making the connection: a way of deriving coherence norms from psychologically loaded semantics. Start with the classical case. Truth (truth value 1) is associated with certainty (credence 1). Falsity (truth value 0) is associated with utter rejection (credence 0). Think of inaccuracy as a way of measuring how far a given partial belief is from the actual truth value; and interpret the “external norm” as telling you to minimize overall inaccuracy in this sense.
If we make suitable (but elegant and arguably well-motivated) assumptions about how “accuracy” is to be measured, then it turns out probabilistic belief states emerge as a special class in this setting. Every improbabilistic belief state can be shown to be accuracy-dominated by a probabilistic one—-there’s some particular probability that’ll be necessarily more accurate than the improbability you started with. No probabilistic belief state is dominated in this sense.
Any violations of formal coherence norms thus turns out to be needlessly far from the ideal aim. And this moral generalizes. Taking the same accuracy measures, but applying them to verities as the ideals, we can prove exactly the same theorem. Anything other than the Smith-Macfarlane belief states will be needlessly distant from the ideal aim. (This is generated by an adaptation of Joyce’s 1998 work on accuracy and classical probabilism—see here for the generalization).
There’s an awful lot of philosophy to be done to spell out the connection in the classical case, let alone its non-classical generalization. But I think even the above sketch gives a view on how we might not only psychologically load a non-classical semantics, but also use that loading to give a semantically-driven rationale for requirements of formal coherence on belief states—and with the Schiffer loading, we get the Macfarlane-Smith approximation to Schifferian coherence constraints.
Suppose we endorsed the psychologically-loaded, semantically-driven theory just sketched. Compare our stance to a theorist who endorsed the psychology without semantics—that is, they endorsed the same formal coherence constraints, but disclaimed commitment to verities and their accompanying ideal states. They thus give up on the prospect of giving the explanation of the coherence constraints sketched above. We and they would agree on what kinds of psychological states are rational to hold together—including what kind of VPB one could rationally take to p when you judge p to be borderline. So they could both agree on the doxastic role of the concept of “borderlineness”, and in that sense give a psychological specification of the concept of indeterminacy. We and they would be allied against rival approaches—say, the claims of the epistemicists (thinking that borderlineness generates uncertainty) and Field (thinking that borderlineness merits nothing more than straight rejection). The fan of psychology-without-semantics might worry about the metaphysical commitments of his friend’s postulate of a vast range of fine-grained verities (attaching to propositions in circumstances)—metasemantic explanatory demands and higher-order-vagueness puzzles are two familiar ways in which this disquiet might be made manifest. In turn, the fan of psychologically loaded, semantically driven theory might question his friend’s refusal to give any underlying explanation of the source of the requirements of formal coherence he postulates. Can explanatory bedrock really be certain formal patterns amongst attititudes? Don’t we owe an illuminating explanation of why those patterns are sensible ones to adopt? (Kolodny mocks this kind of attitude, in recent work, as picturing coherence norms as a mere “fetish for a certain kind of mental neatness”). That explanation needn’t take a semantically-driven form—but it feels like we need something.
To repeat the basic moral. Classical semantics, as traditionally conceived, is already psychologically loaded. If we go in for non-classical semantics at all (with more than instrumentalist ambitions in mind) we underspecify the theory until we’re told what what the psychological loading of the new semantic values is to be. That’s one kind of complaint against non-classical semantics. It’s always possible to kick away the ladder—to take the formal coherence constraints motivated by a particular elaboration of this semantics, and endorse only these without giving a semantically-driven explanation of why these constraints in particular are in force. Repeating this stance, we can find pairs of views that, while distinct, are importantly allied on many fronts. I think in particular this casts doubt on the kind of argument that Schiffer often sounds like he’s giving—i.e. to argue from facts about appropriate psychological attitudes to borderline cases, to the desirability of a “psychology without semantics” view.
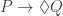 —where the modal expresses an idealized ignorance). The second is an interesting epistemic constraint on true counterfactuals I call “Bennett’s Hypothesis”.
—where the modal expresses an idealized ignorance). The second is an interesting epistemic constraint on true counterfactuals I call “Bennett’s Hypothesis”.
You must be logged in to post a comment.